在前一篇文章中,详细介绍了流是什么,与集合的区别,操作流时需要注意的一些特性和规则,以及 java.util.Stream.stream 类中提供的流操作分类。这篇文章我们就来详细介绍一下具体的几个不容易理解的流操作。
映射操作
Map 函数
Map映射函数的方法签名如下所示,它接受一个 mapper 行为参数,而 mapper 行为参数将会接受一个 T 类型的参数,并返回一个 R 类型的值:1
<R> Stream<R> map(Function<? super T, ? extends R> mapper)
理解Map映射函数的关键在于,参数 T 经过 mapper 行为参数映射后返回的 R 值将会被Map函数包装成Stream<R>值。继续上一篇提到的菜单列表例子,假如需要返回每项菜的名字,我们可以这样实现:1
2
3 List<String> dishNames = menus.stream()
.map(dish -> dish.getName()) //此处map返回值为Stream<String>, dish来源于Stream<Dish>
.collect(Collectors.toList())
换句话说,流水线中的元素都是Stream类型的。
FlatMap 函数
FlatMap 函数的方法签名如下所示,它接受一个 mapper 行为参数,而 mapper 行为参数将会接受一个 T 类型的参数,并返回一个 Stream<? extends R > 类型的值:1
<R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper)
FlatMap 函数有点类似于 Map 函数,但是核心区别就在于它的 mapper 函数的返回值为 Stream<? extends R >,它返回后 flatMap 函数不会再将结果包装成Stream<Stream<? extends R>> 类型值。举个例子,假设有一个字符串列表["Hello","World"],需要返回一个不包含重复字符的列表,我们可以这样实现:1
2
3
4 List<String> distinctChars = words.stream()
.map(word -> word.split(" ")) //返回Stream<String[]>
.distinct()
.collect(Collectors.toList())
很可惜,该写法将会得不到正确地结果,原因就在于map 函数返回的值为Stream<String[]>,而传递给 distinct 函数处理时,是处理的字符串数组类型String[],并不是字符串类型,这个时候就需要使用 flatMap 函数,它能将String[]类型流化后再返回,即Arrays.stream(String[])后再返回。flatMap 函数是一个能将一个流元素映射成另一个包含多个元素的新流的具有副作用的函数,也即扁平化。1
2
3
4 List<String> distinctChars = words.stream()
.flatMap(word -> Arrays.stream(word.split(""))) //返回Stream<String>
.distinct()
.collect(Collectors.toList())
可以用如下图来区分 map 和 flatMap 函数处理前后的对比: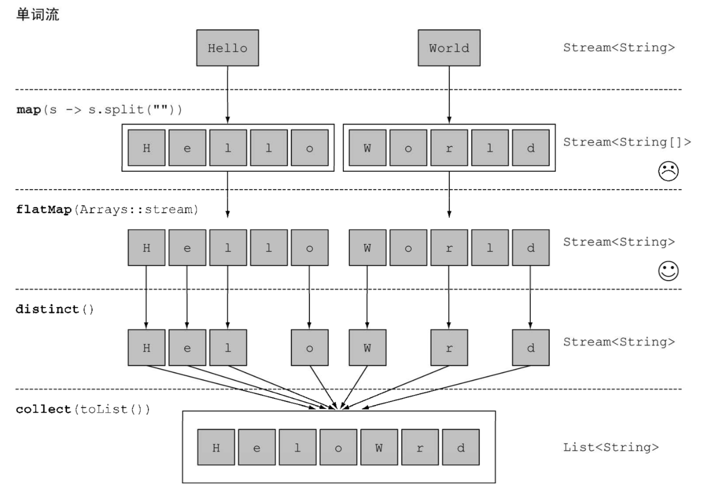
Map 和 FlatMap函数还有针对IntStream、DoubleStream、LongStream三种特殊流的对应操作。
归约操作
Reduce 函数
Reduce 函数成为归约操作,它能将流水线归约成一个非流的最终值,它有如下三种形式,其中 identity 为类型 T 的初始累积变量,accumulator 行为参数称为累加器,它接受两个参数,一个代表 identity 的累积变量,一个为流中的元素,并返回新的 identity,而 combiner 行为参数称为连接函数,在并行处理时,它能将identity1 和 identity2 这两个中间的累积变量连接起来生成最终的结果并返回:1
2
3T reduce(T identity, BinaryOperator<T> accumulator)
Optional<T> reduce(BinaryOperator<T> accumulator)
<U> U reduce(U identity,BiFunction<U, ? super T, U> accumulator,BinaryOperator<U> combiner)
例如,假设需要返回菜单中所有菜品 calories 的总和,我们可以这样实现:1
2
3
4
5
6
7
8int sum = menus.stream().map(dish -> dish.getCalories())
.reduce(0, (a, b)-> a + b);
Optional<Integer> sum2 = menus.stream().map(-> dish.getCalories())
.reduce((a,b)->a + b);
int sum3 = menus.parallelStream().map(-> dish.getCalories())
.reduce(0,(a,b)-> a+b,(sum1, sum2)-> sum1 + sum2)
注意,在第二种实现中,没有提供初始的 identity 时将会返回一个Optional 类型的值,表示此时的结果是不确定的,流可能为空,可以通过Optional判断是否有值返回;第三种实现,可以更好地并行处理,而且可以将类型 T 映射到类型 U 返回,但是要求 combiner 函数需要满足结合性(Associativity)。
收集操作
Collect 函数
Collect 函数本质上是一个归约操作,区别就在于它是一个可变的归约操作,一般会将结果归约到一个可变的容器中,比如 ArrayList、Set等。第一种Collect 方法签名如下所示,它接受三个参数,第一个 supplier 行为参数将会产生一个 R 类型的可变容器; 第二个 accumulator 行为参数将会接受两个参数,第一个参数是 supplier 行为参数返回的可变容器,第二个参数是类型为 T的流中的元素,并返回一个 R 类型的可变容器;第三个 combiner 行为参数也会接收两个可变容器参数,并返回这两个可变容器的连接结果,其最终将会是 R 类型的可变容器中存放了 T 类型的元素:1
<R> R collect(Supplier<R> supplier, BiConsumer<R,? super T> accumulator, BiConsumer<R,R> combiner)
比如,假设需要返回菜品的名字列表,可以这样实现:1
2
3
4
5List<String> dishNames = menus.stream()
.map(dish -> dish.getName)
.collect(new ArrayList(),
(list, name) -> list.add(name),
(list1, list2) -> list1.add(list2))
注意在这种情况下,Collect 函数执行的特征为,IDENTITY_FINISH和 CONCURRENT但并非UNORDERED的收集器,在这种情况下,如果集合中的元素时有序的,将会顺序处理,如果是无序的集合将会并行处理。
Collect 方法签名的第二种形式如下所示,它接收一个 Collector 参数:1
<R,A> R collect(Collector<? super T,A,R> collector)
Collector 参数是一个接口,它的最终语义是将会收集 T 类型的流中元素,并最终返回一个R类型的值(通常但不一定是集合),中间累加器的类型为 A,它的内容如下所示:1
2
3
4
5
6
7public interface Collector<T, A, R> {
Supplier<A> supplier();
BiConsumer<A, T> accumulator();
Function<A, R> finisher();
BinaryOperator<A> combiner();
Set<Characteristics> characteristics();
}
它跟 Collect 函数三个参数的形式的区别就在于可以定义 finisher 行为参数和characteristics 特征。finsher 行为参数必须返回在累积过程的最后要调用的一个函数,以便将累加器对象转换为整个集合操作的最终结果,如果累加器对象恰好符合预期的最终结果,因此无需进行转换,所以finisher方法只需返回identity函数。从这里也可以看出实现 Collector 接口,最终的结果可以不一定返回一个可变的容器; characteristics 方法将会返回一个Characteristics集合,这个集合可以包含如下三个参数的组合:
- UNORDERED——归约结果不受流中项目的遍历和累积顺序的影响。
- CONCURRENT——accumulator函数可以从多个线程同时调用,且该收集器可以并行归约流。如果收集器没有标为UNORDERED,那它仅在用于无序数据源时才可以并行归约。
- IDENTITY_FINISH——这表明完成器方法返回的函数是一个恒等函数,可以跳过。这种情况下,累加器对象将会直接用作归约过程的最终结果。这也意味着,将累加器A不加检查地转换为结果R是安全的。
接着上面的例子,我们可以自定义一个 Collector 的实现,达到相同的结果:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30import java.util.*;
import java.util.function.*;
import java.util.stream.Collector;
import static java.util.stream.Collector.Characteristics.*;
public class ToListCollector<T> implements Collector<T, List<T>, List<T>> {
public Supplier<List<T>> supplier() {
return ArrayList::new;
}
public BiConsumer<List<T>, T> accumulator() {
return List::add;
}
public Function<List<T>, List<T>> finisher() {
return Function.indentity();
}
public BinaryOperator<List<T>> combiner() {
return (list1, list2) -> {
list1.addAll(list2);
return list1;
};
}
public Set<Characteristics> characteristics() {
return Collections.unmodifiableSet(EnumSet.of(
IDENTITY_FINISH, CONCURRENT));
}
}
注意这种情况下,将不会并行处理,因为List是有序的。
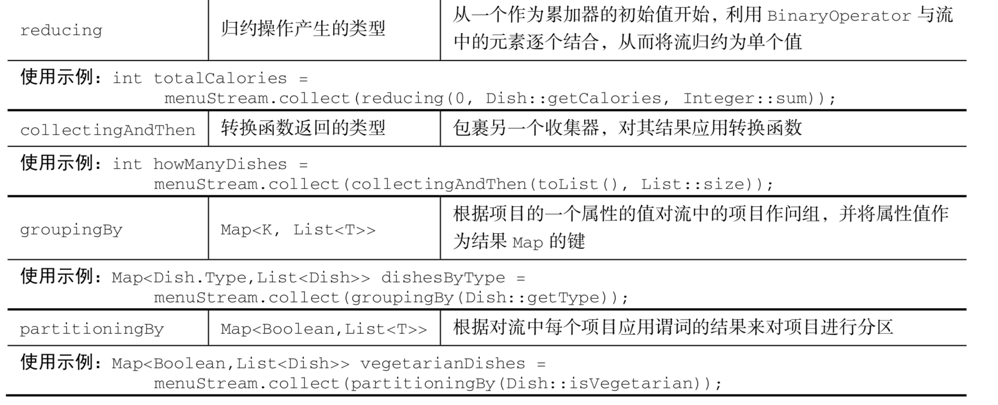
此外,java.util.stream.Collectors 类中提供了大量的工厂方法,可以直接使用,如下所示:

以上就是在使用流 API 时,需要重点注意的操作,理解到位了,就能很好地写出优雅的流式代码,也会从此爱上函数式编程模型。